Table of Contents
Market research has proven that about 70% of new information merchandise fail or leave out their revenue. The predominant cause is that they fail to apprehend their buyers and desire to comply with the fit-all approach.
Personalization is a critical factor in handling this problem. Studies exhibit that ~ 60% of the shopper’s skilled personalization agreed that it has a disproportionate effect on their engagement and decision.
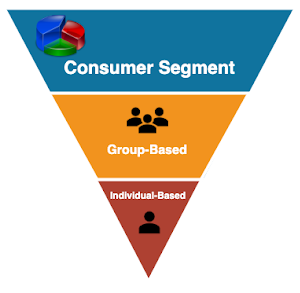
As proven in the following image, the first thing in the personalization funnel is purchaser segmentation. Consumer segmentation helps any online enterprise to the center of attention and goal its target audience and grant extra personalization for the team of customers or individuals. 88% of online groups have observed substantial enhancements in their enterprise vital metrics like engagement and monetization with desirable customer segmentation. 53% of them have mentioned that they received a carry of over 10%.
In this post, we talk about our answer to client segmentation at realtor.com. Our method is broadly speaking, primarily based on customer experience segmentation. In this approach, we aim to apprehend which stage of the domestic shopping for manner our buyers are in. By knowing our purchaser stage, we should supply greater customized offerings for them, like higher recommendations, customized content, and run top-quality advertising campaigns, to title a few. We predict client levels primarily based on their historical interactions with our internet site content to do this segmentation. We used a desktop, getting to know to expect the client stage.
In the subsequent section, we will furnish our system to outline the customer stage and how we used computing device studying to predict the person stage.
Buyer Stage Definition Procedure
Defining the purchaser stage formally is a difficult task. People from extraordinary divisions with specific know-how like customer research, product, and engineering need to collaborate. It is also one of a kind from commercial enterprise to any other enterprise context and wishes to contain humans who be aware of commercial enterprise context very well.
After having these discussions and collaborations to outline the customer stage in the actual property domain, we ended up with some formal and equal definitions for the domestic client stages. Our most crucial subsequent project is to pick out the report that should have higher predictive effects, or in different words, ML algorithms or machines may want to research it better.
We ran special surveys and requested our clients some questions which should uniquely phase them in unique stages. Then we used these surveys to label our customers’ behavioral information like how they used our website, how tons they spent on every page, etc. We used this tagged information and did coaching and validating specific ML fashions to choose the excellent definition. We selected the report that had higher predictive outcomes (precision/recall in our case). That definition is used as our floor fact to outline domestic customer stages. The following determine indicates our manner to pick out a high-quality purpose.
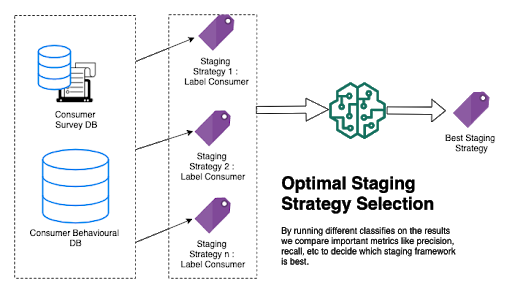
By the usage of this approach, we chose our quality definition for staging our consumers.
In the subsequent section, we will provide an assessment of how we architected and designed the ML mannequin and associated pipelines for person segmentation.
Buyer Stage ML Model Design
The primary venture in modeling is constructing an ML mannequin that may want to predict the person stage based totally on his or her behavioral facts from our facts lake. To reap this aim, we divided our labeled information set into education and trying out statistics sets. We used AWS SageMaker as our toolchain to put in force and diagram the mannequin as proven in the following picture.
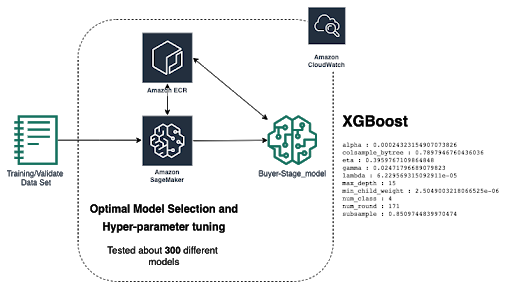
Our information set carries about 250 unique facets of personal behavior. We leverage SageMaker AutoML to locate and tune the social algorithms, and we use XGboost as our fundamental solution. Once we construct our mannequin, we examined our take a look at the facts set to see the results. We used precision/recall as the principal metric for our mannequin performance.
Precision (also known as tremendous predictive value) is the fraction of practical situations amongst the retrieved instances. At the same time, recall (also recognized as sensitivity) is the fraction of the complete quantity of applicable cases retrieved. Both precision and recall are consequently primarily based on an appreciation and measure of relevance.
For example, if we understand that we have a hundred Dreamer users in our trying out facts set, and our mannequin returns eighty customers as Dreamer. We comprehensively 60 of them are Dreamer, then mannequin precision will be 60/80 or 75%. On the different hand, the recall will be 60/100, which is 60%. In this case, the precision is “how beneficial the outcomes are, “and memory is “how entire the effects are. ” We performed a common of 89% in accuracy and 75% recall, which is promising outcomes for our baseline model.
We used AWS SageMaker and QuickSight for realizing this checking out and offline trying out manner as proven below.
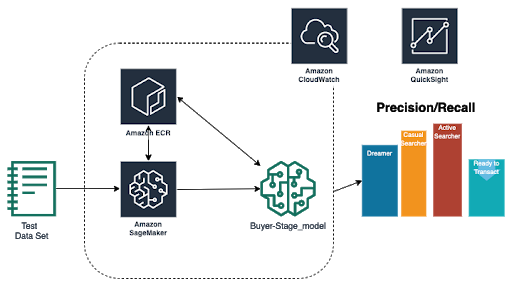
In the subsequent section, we will evaluate the structure that we used to produce this service.
Buyer Stage ML Pipeline Server less Architecture
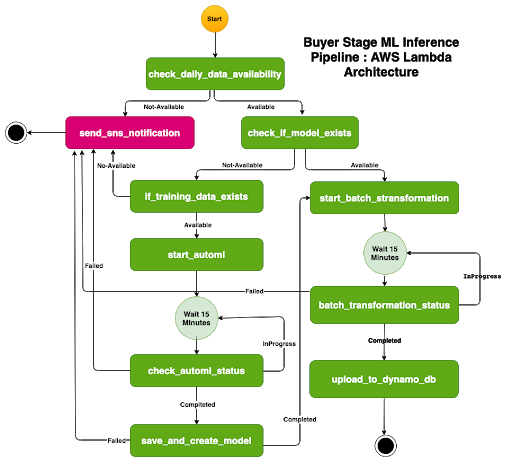
To format the device, we divide it into two unique pipelines: the ETL pipeline and the 2nd one is the ML pipeline. The first one is accountable for making associated statistics for ML inferencing. The system is identical as we construct our education records set. We, broadly speaking, using the Apache spark for doing the task. The ML pipeline is accountable for following the mannequin on facts generated using the ETL pipeline and add the users’ stage prediction. We used AWS step functions, SageMaker, Lambda, Glue, and DynamoDb to construct the ML pipeline. The following image suggests the ml pipeline country machine.
As it is described, the ML pipeline assessments, if every day, statistics are accessible for inferencing. If it is now not, then it will ship an SNS notification. If it receives an error in any of the states, it will send SNS notification to notify the machine admin.
When each day records are on hand, then it will take a look at for the model. If a dummy is no longer handy, it will construct a mannequin using SageMaker Autopilot. It makes use of education statistics set to build models. Once the form is equipped, it will do batch inferencing to predict the person stage. The stage facts will be pushed into DynamoDb, the usage of AWS Glue for different applications.
Conclusions
In this weblog post, we temporarily reviewed our client segmentation pipeline and how we approached the problem. We proceed to enhance the modern-day mannequin and work more excellent on customized information merchandise at rentbuynsell.com.

{kind=link}